Objective
The paper attempts to create and test a Neural Network Architecture which is capable of learning high level concepts using unlabeled images. This method is used to detect Human Faces, Human Bodies and Cats.
Training Set Construction
The training dataset was constructed by sampling framesfrom 10 million YouTube videos. To avoid duplicates, only one image per video was added to the dataset. Each example is a color image with 200x200 pixels. To check the proportion of faces in the dataset, the OpenCV face detector was run on 60x60 randomly-sampled patches from the dataset. The number of faces were less than 3% in 100,000 of the randomly sampled patches.
Apart from faces the most common objects on youtube videos are body parts and pets. Similar to faces, a database of images containing human bodies and cats was prepared to train the the net.

Algorithm
Architecture
This algorithm is built upon three ideas-

A small part of the image is mapped to the next layer. This allows for equivariance in local deformations. What this means is that, if an object translates locally in the image, the feature formed in the next layer also moves in the same pattern. Data from a number of such receptive fields are is used to identify the nature of deformation. "Pooling", which is explained below then removes this deformation. Although local receptive fields are used, the network is not convolutional: the parameters are not shared across different locations in the image.
The output of nearby "Locally Receptive Neurons" are taken, pooled together and passed on to the next layer. Pooling typically involves taking the average of the outputs or the Maximum of the outputs. This algorithm uses L2 poooling.
This architecture can be viewed as a sparse deep autoencoder. It was constructed by replicating three times the same stage composed of local filtering, local pooling and local contrast normalization. The output of one stage is the input to the next one and the overall model can be interpreted as a nine-layered network (see Figure).
Learning and Optimization
During learning, the parameters of the second sublayers (H) are fixed to uniform weights, whereas the encoding weights W1 and decoding weights W2 of the first sublayers are adjusted using the optimization problem - "Reconstruction Topographic Independent Component Analysis".
Test
Experimental Protocols
After training the network, it was given a test set of 37,000 images. The set had a mixture of faces and distractor objects.
The cat face images are collected from the dataset described in (Zhang et al., 2008). The Human body dataset was created by subsampling at random from a benchmark dataset (Keller et al., 2009). In both the sets negative images were added from the ImageNet dataset.
The performance of the network was rated in the terms of the classification accuracy of the best Neuron. For each Neuron, the maximun and the minimun activation values were noted. The difference between the minimum and maximum activation values was divided into 20 levels. The reported accuracy is the best classification accuracy among 20 thresholds.
Results
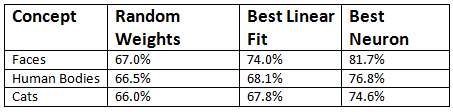
The first two columns show results for method that do not require training. In the "Random Weights", column the the same network architecture is used but the weights have just been initialized randomly, without any training. The "Linear Fit" column shows the result of the best linear filters selected from 100,000 examples sampled from the training set.
The last column, shows the result by considering the Experimental Protocols mentioned above. The rate of accuracy for the best neuron here is 81.7% far more than that of the linear filters. This architecture also outperforms standard baselines in terms of recognition rates of cats and human body, achieving a 10% better accuracy.
Object Recognition
The performance of the algorithm to recognize objects, was a leap over the previous best. With 20,000 categories, this method achieved a 70% relative improvement over the previous best result.