Kranti Kumar Parida 1,
Neeraj Matiyali1,
Tanaya Guha2,
Gaurav Sharma3
1IIT Kanpur, 2University of Warwick, 3NEC Labs America
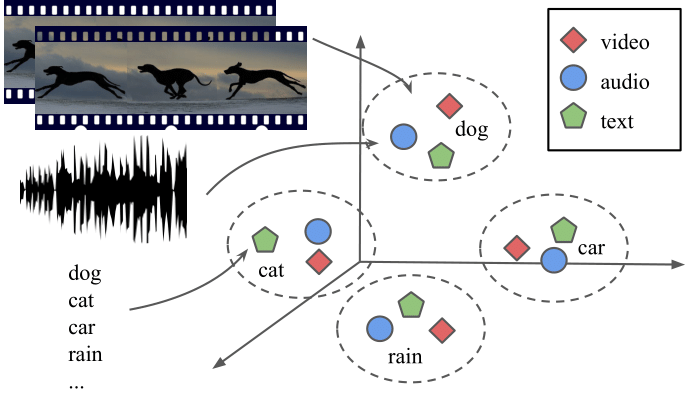
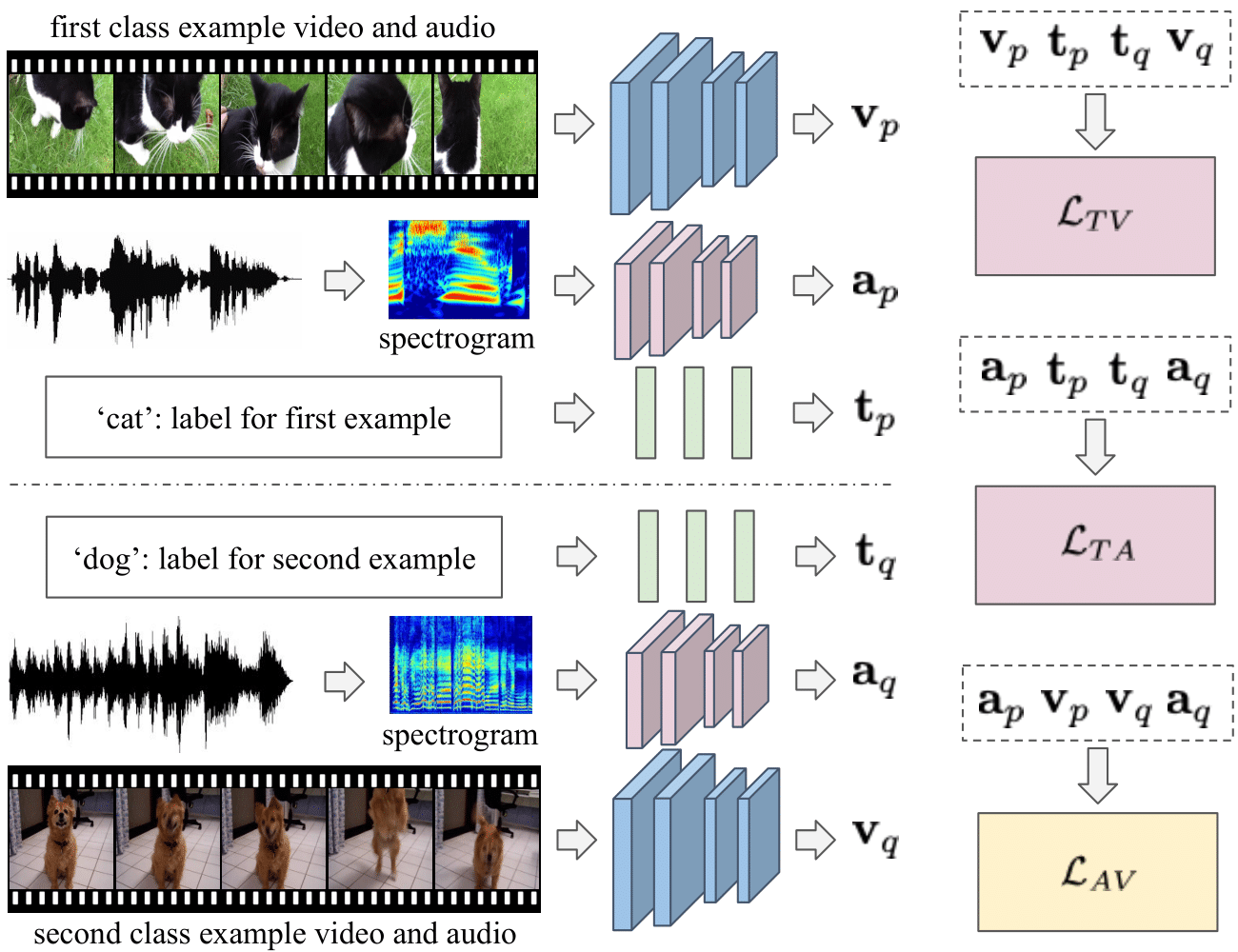
We present an audio-visual multimodal approach for the task of zeroshot learning (ZSL) for classification and retrieval of videos. ZSL has been studied extensively in the recent past but has primarily been limited to visual modality and to images. We demonstrate that both audio and visual modalities are important for ZSL for videos. Since a dataset to study the task is currently not available, we also construct an appropriate multimodal dataset with 33 classes containing 156, 416 videos, from an existing large scale audio event dataset. We empirically show that the performance improves by adding audio modality for both tasks of zeroshot classification and retrieval, when using multimodal extensions of embedding learning methods. We also propose a novel method to predict the ‘dominant’ modality using a jointly learned modality attention network. We learn the attention in a semi-supervised setting and thus do not require any additional explicit labelling for the modalities. We provide qualitative validation of the modality specific attention, which also successfully generalizes to unseen test classes.