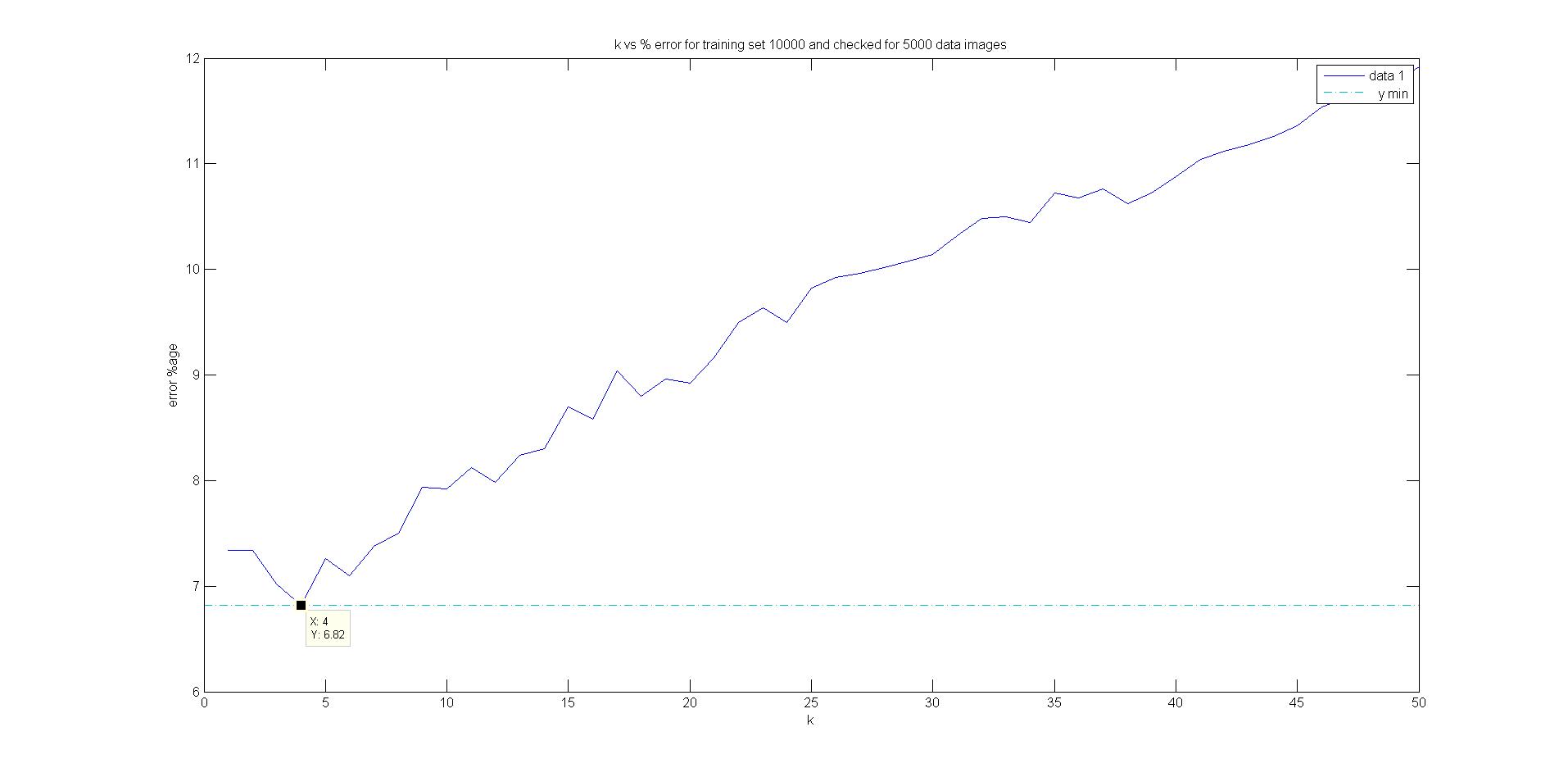
In this part, I have considered training set of first 10000 images from MNIST training set and checked for 5000 test cases. Plotted a graph for k=1:50 and k for which minimum error is 4. First, the rows of the data matrix of MNIST data classifies into groups using labels. k nearest neighbours are used to decide the class of data depending upon max(number of labels of particular digit). After training , it is tested on test sample and error is calculated directly proportional to mismatch with label of tests
In this question, we have considered how an imaging system may construct models for handwritten numerals. We have used 3000 images from the MNIST database, each of size 28x28 pixels.
Residual Variance vs Isomap Dimensionality Curve
Data Distribution of 1 and 7 Digits curve
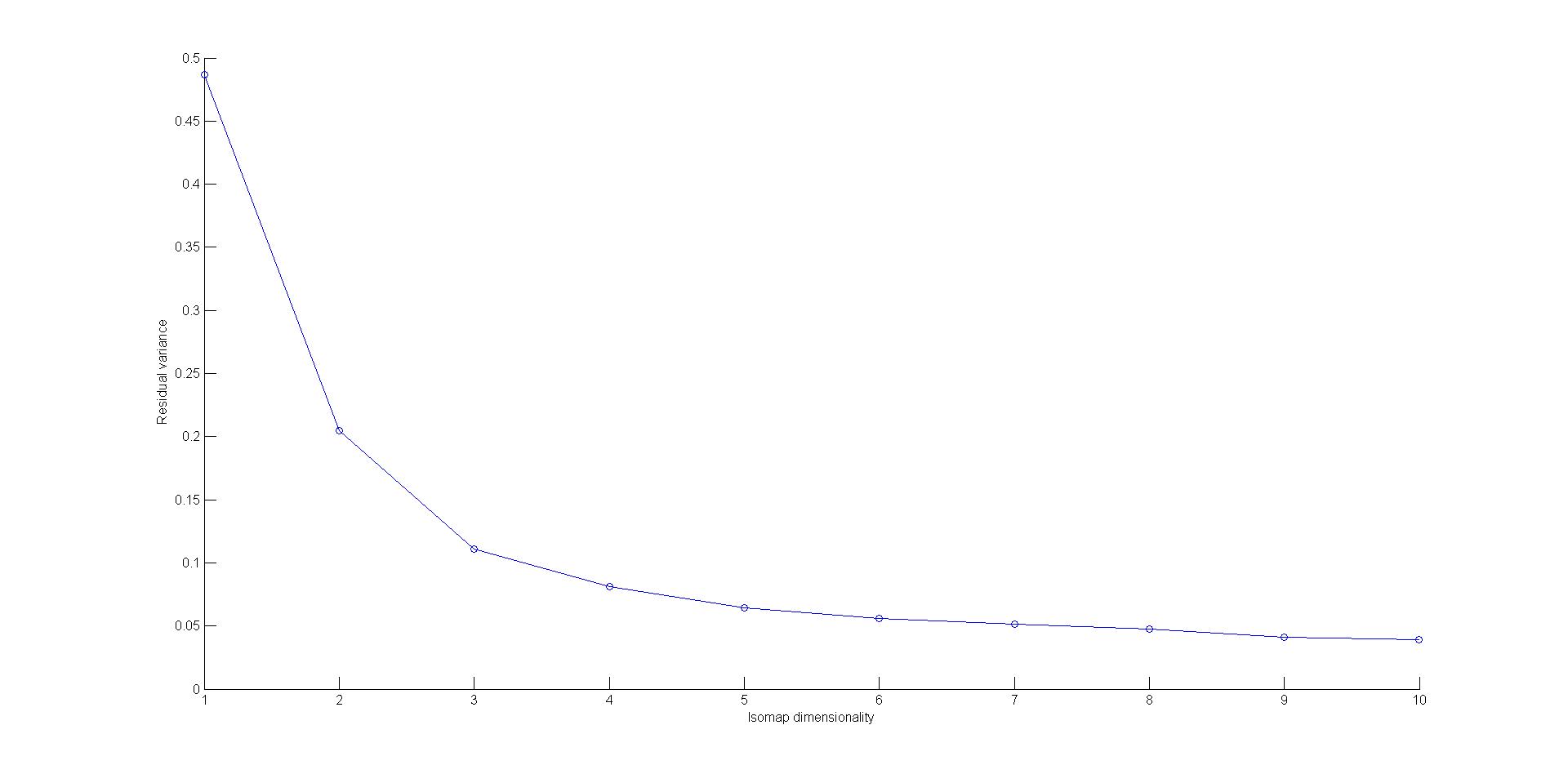
Residual Variance vs Isomap Dimensionality Curve
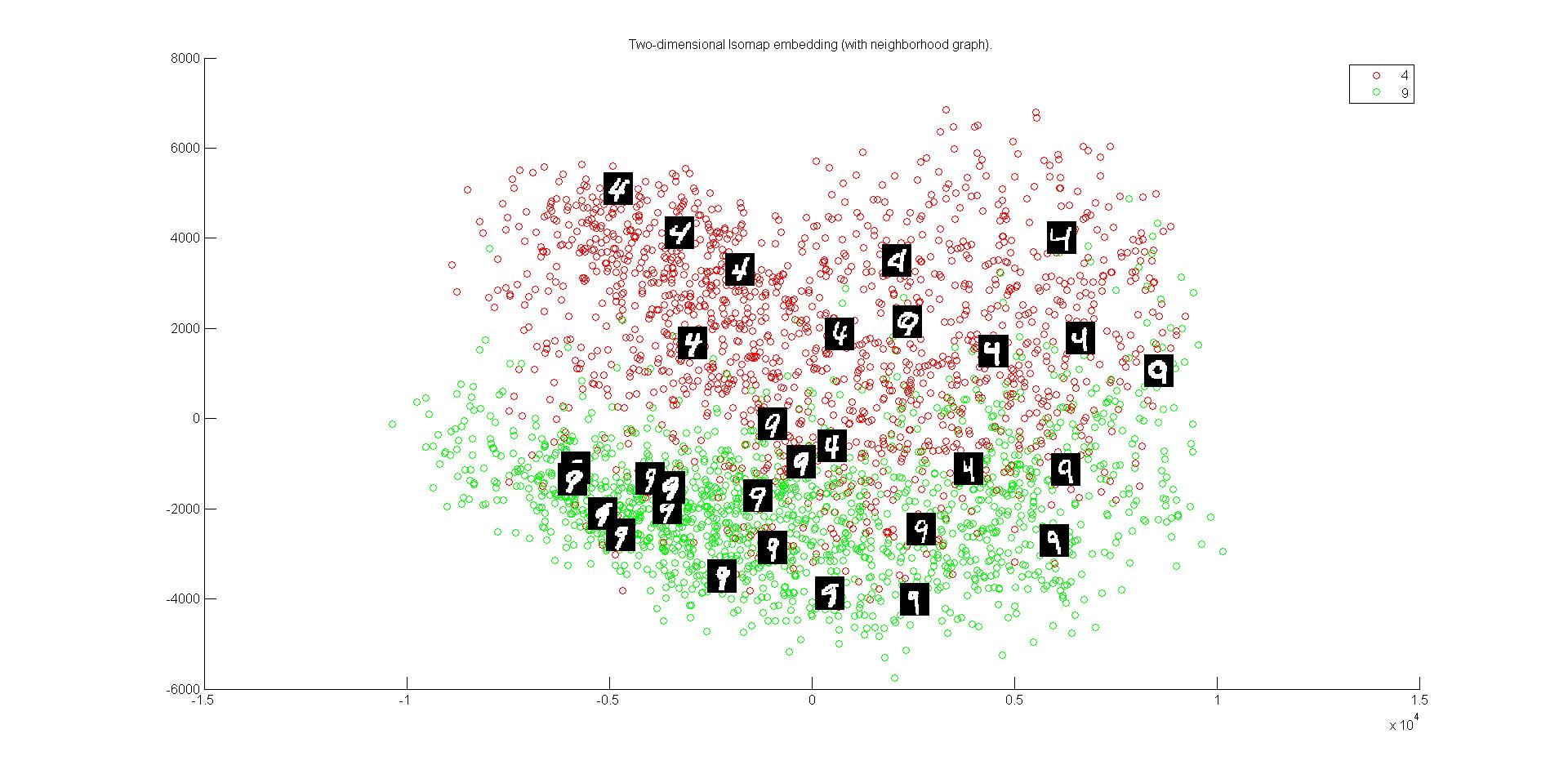
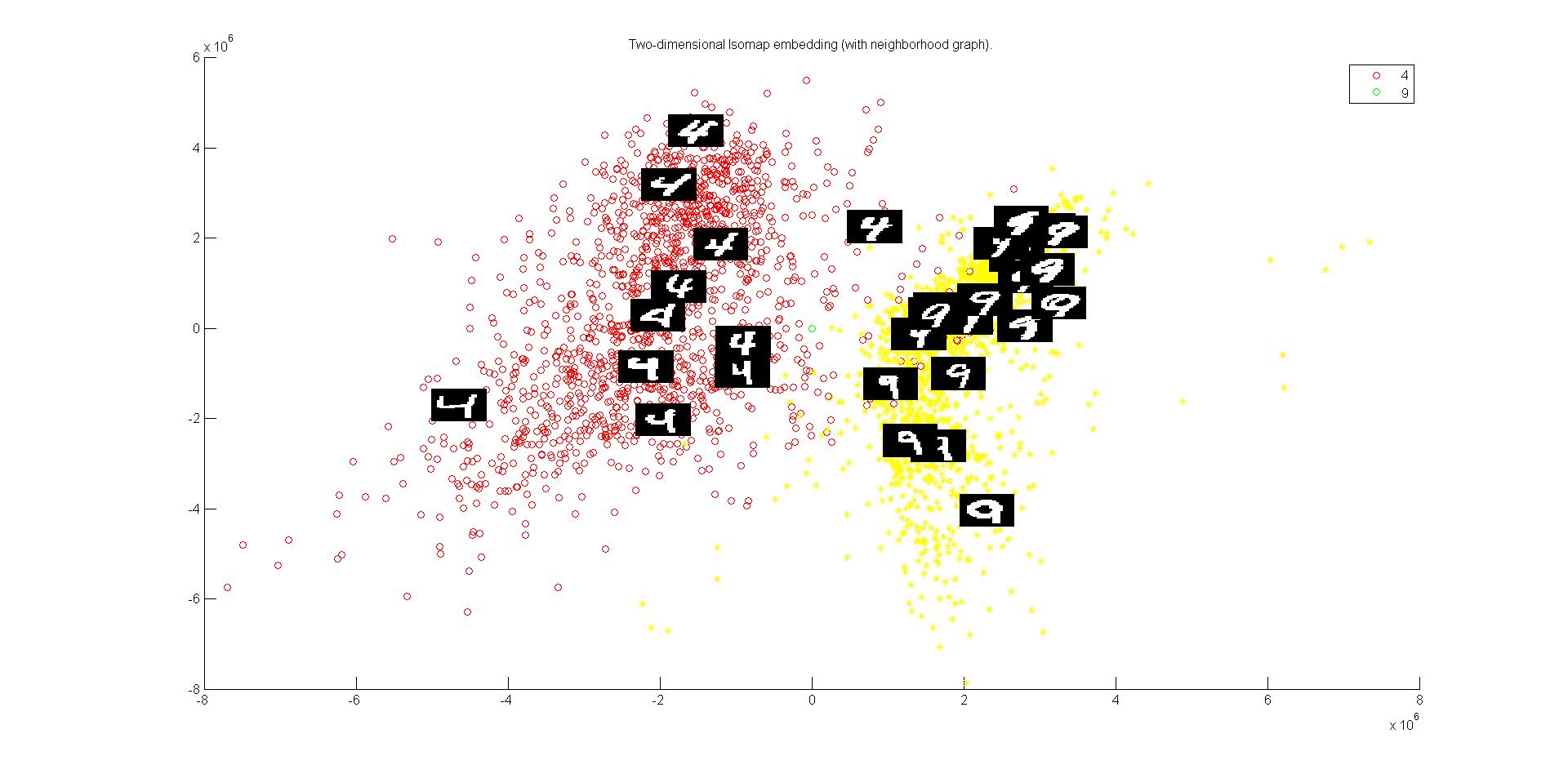
Data Distribution of 4 and 9 Digits curve
Residual Variance vs Isomap Dimensionality Curve
Data Distribution of all Digits curve
Residual Variance vs Isomap Dimensionality Curve
Isomaps as given in Tenenbaum's paper.
Residual Variance vs Isomap Dimensionality Curve
Isomaps as given in Tenenbaum's paper.
Residual Variance vs Isomap Dimensionality Curve
Isomaps as given in Tenenbaum's paper.
In this part,I experiment with various layer architectures, parameters and try to improve the accuracy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}