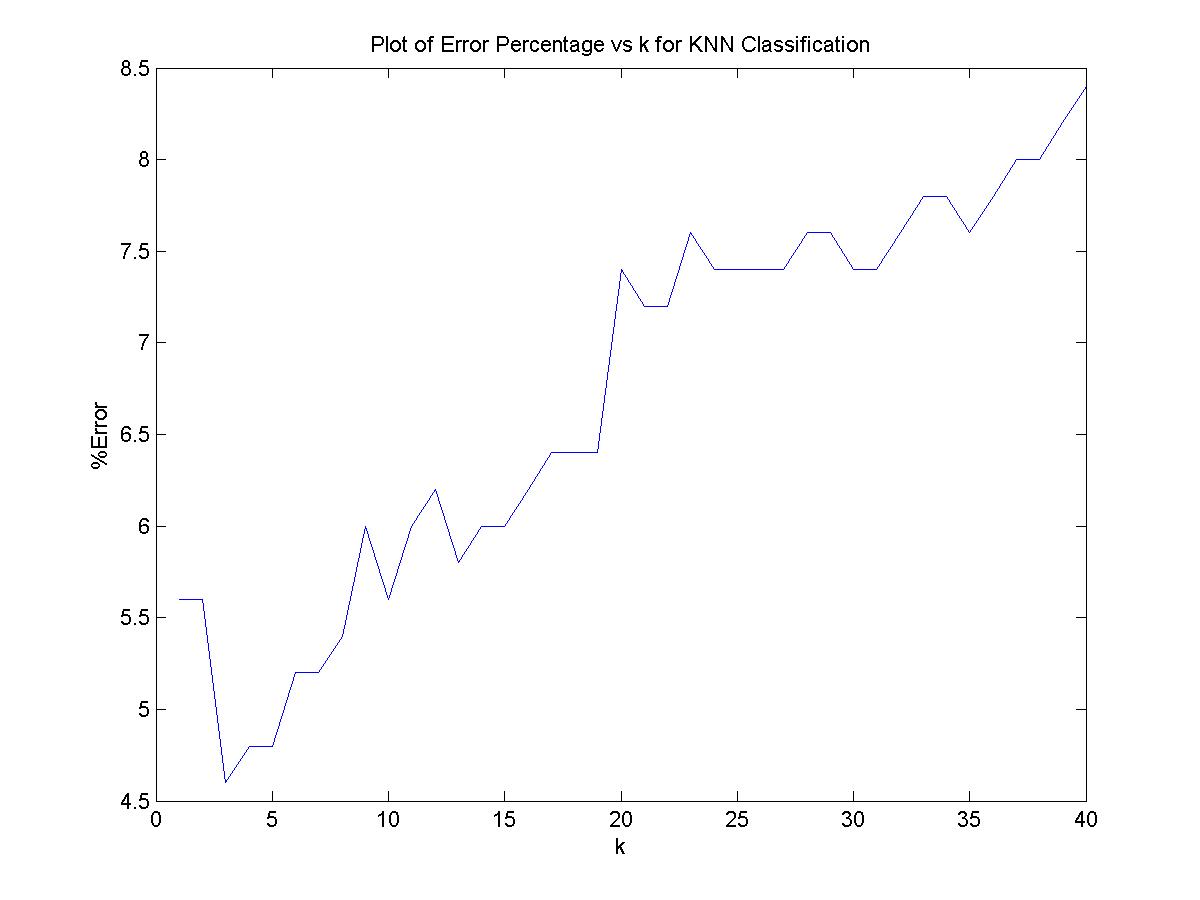
The value of k for which minimum % error occur is 3 minimum % error is 4.6.
Here from the plot we can see the optimum value of k is very much less which is 3 i.e the first odd number after 1. The error happens mainly at the boundaries
where increasing k causes wrong voting.
Isomap:Isomap is a method for low dimensional embedding of high dimensional data. If the high dimensional data is lying on a low dimensional manifold then isomap tries to explore the geometry of data. Here the connectivity is defined by choosing k nearest euclidean neighbours. The geodesic distance between two points is defined by the shortest possible route through graph made by considering each data point as a node. The geodesic distance between points remains preserved in the lower dimensional embedding.
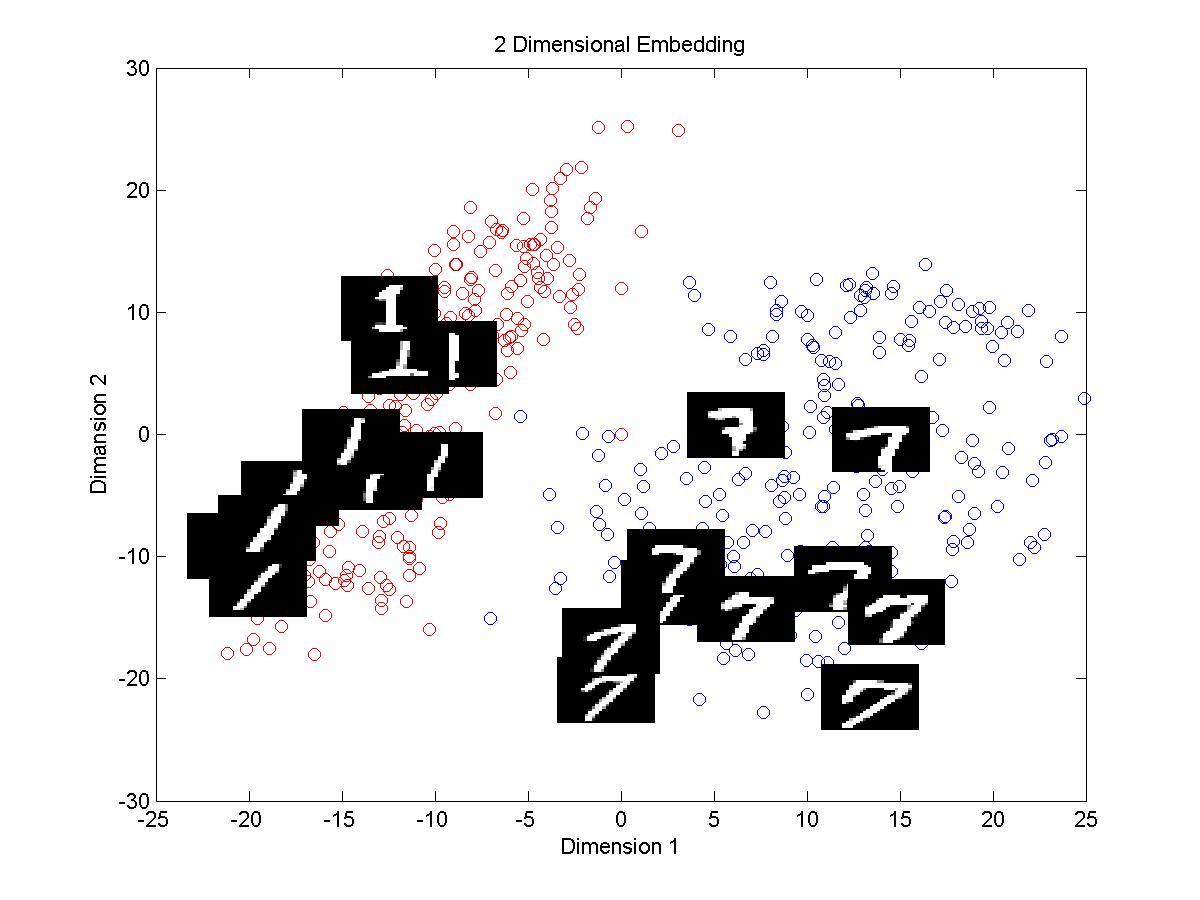
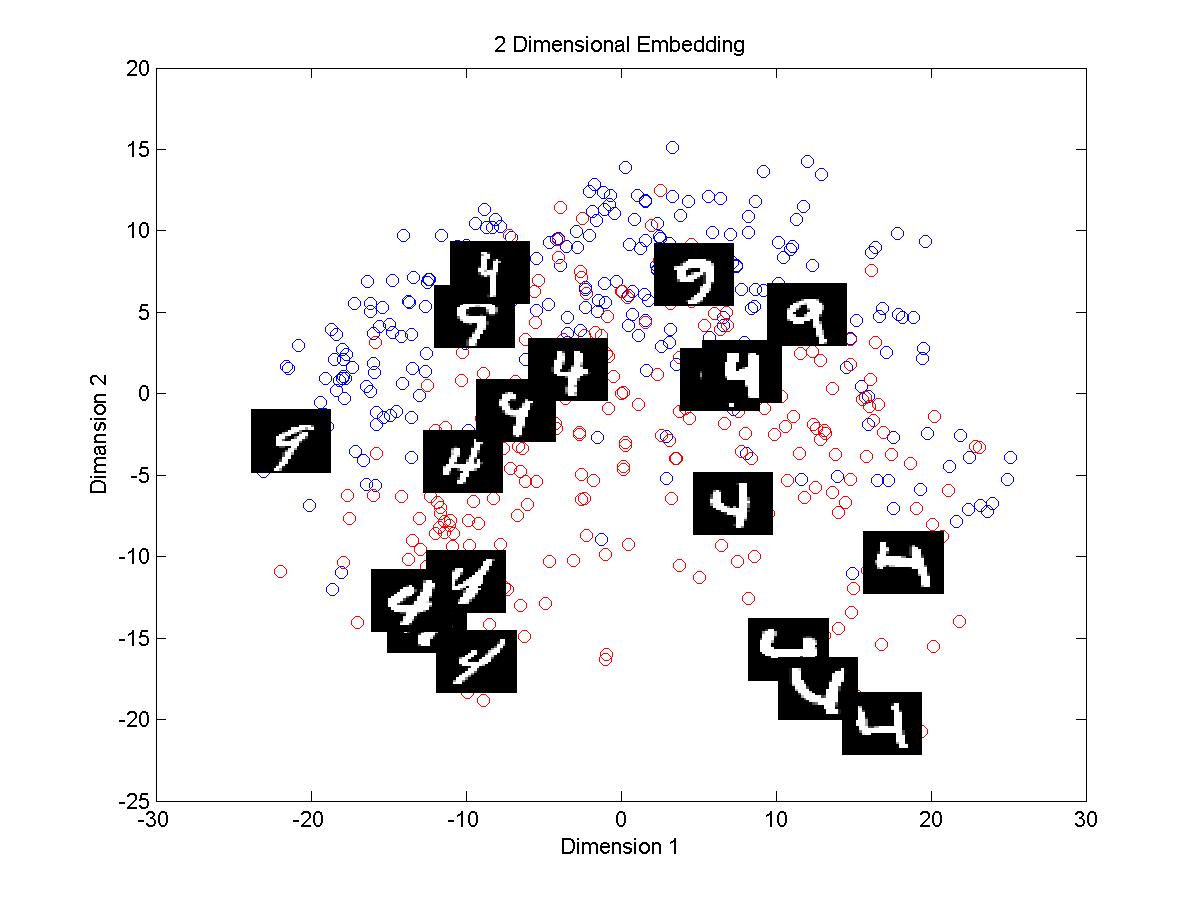
1.First of all tangent distance method takes significantly large amount of time than Euclidean distance method in computing distance matrix.
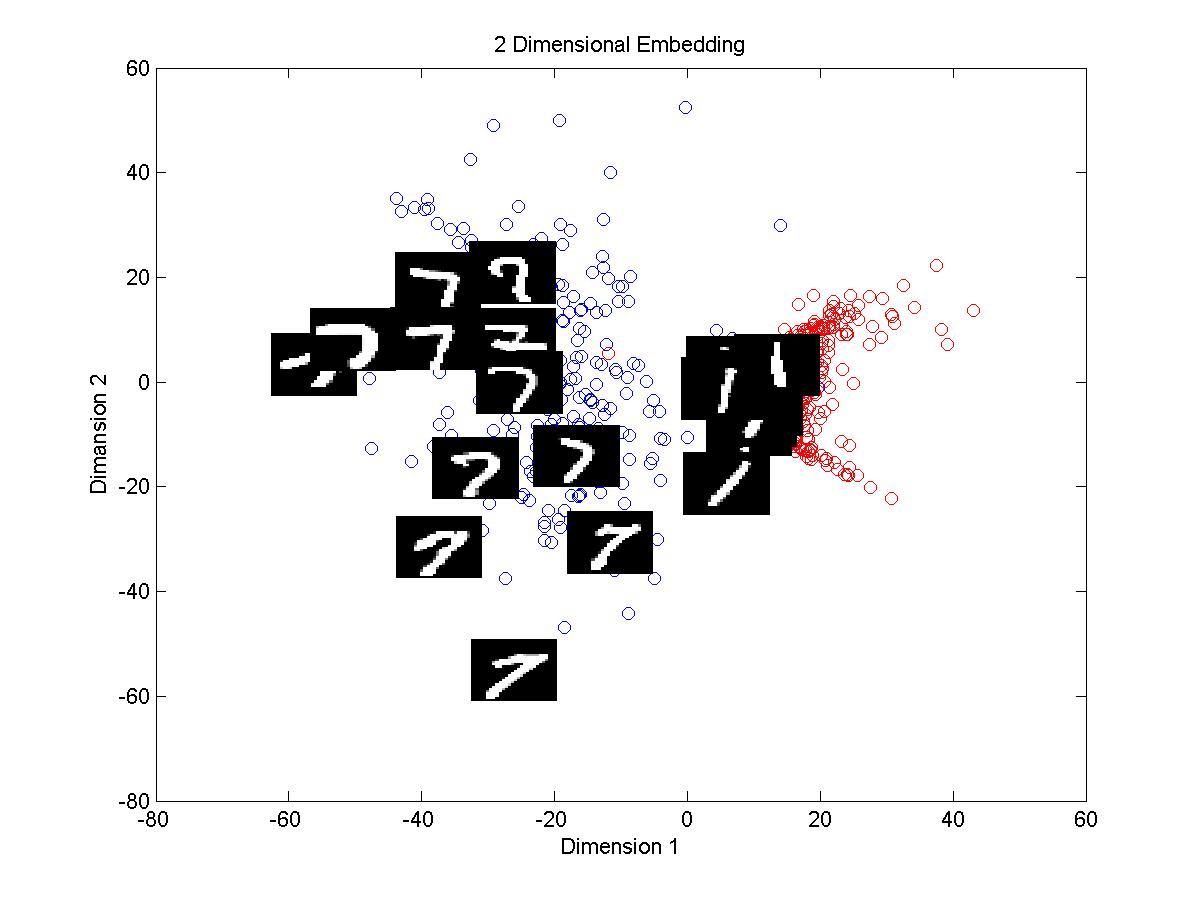
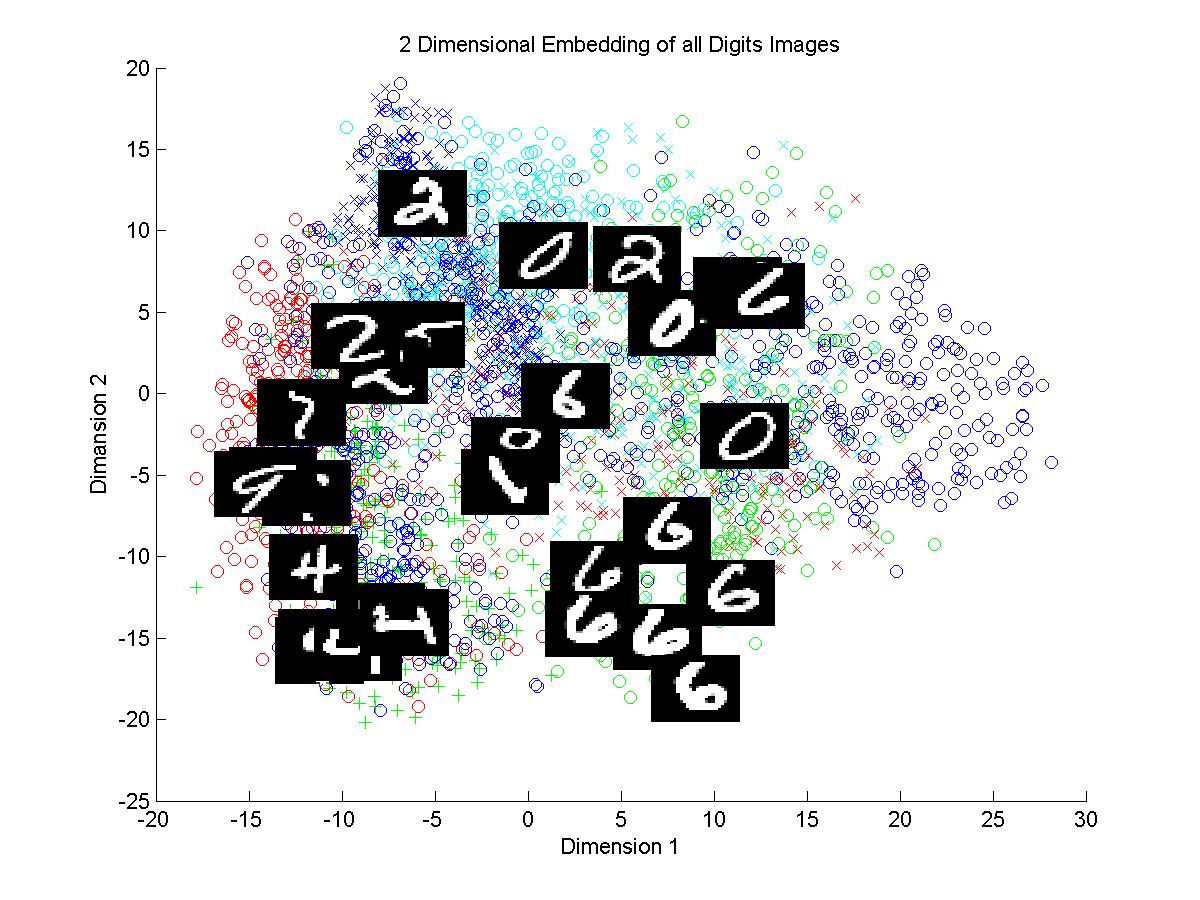
2.From the plots above we can see that in both methods clusters of digits 1 and 7 are discriminated efficiently in the 2D embedding. Cluster of 1 is dense than that of 7 in both cases. Plot with tangent distance looks
more clear and discriminative than the plot made by using euclidean distance.
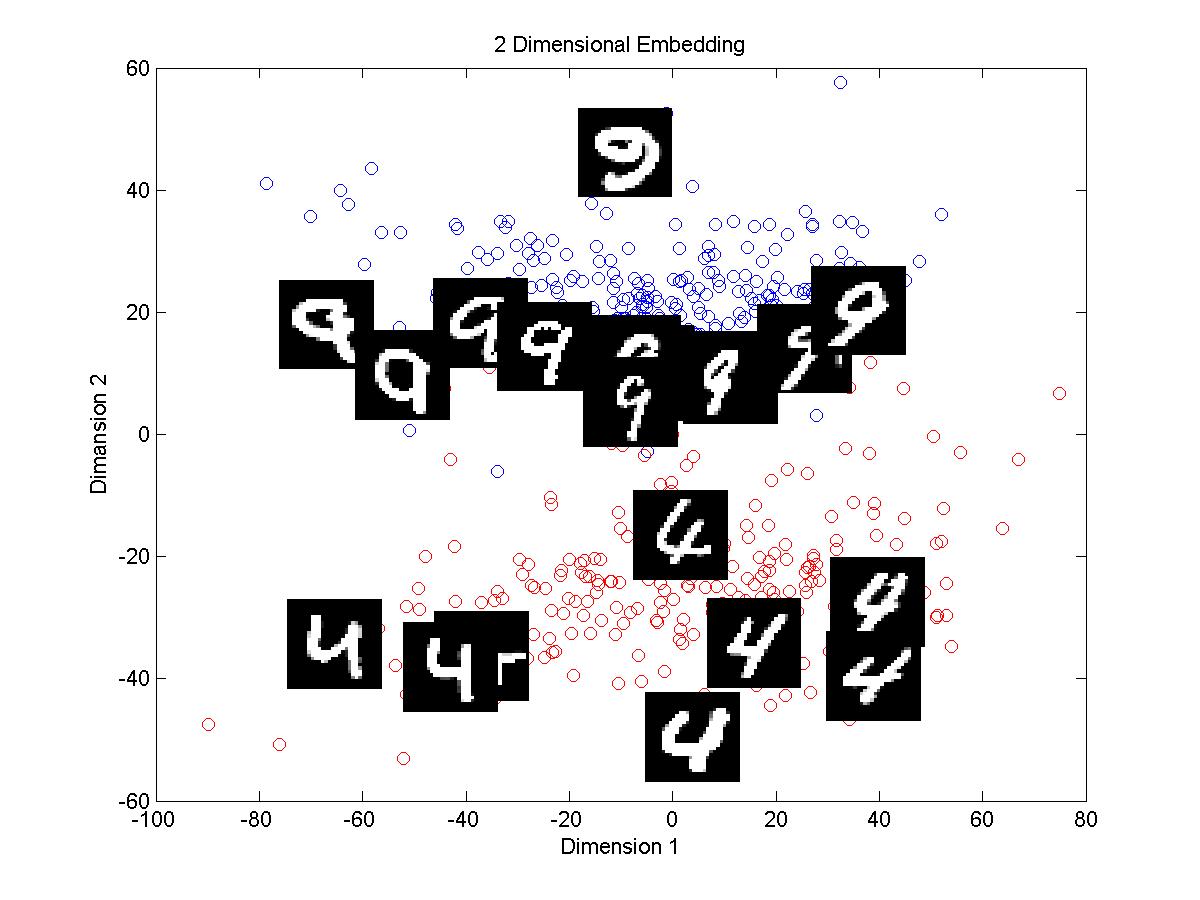
3.For digits 4 and 9 the clusters in case of Euclidean distance are not well separated and the boundary is not sharp. Using tangent distance the clusters formed are well separated.
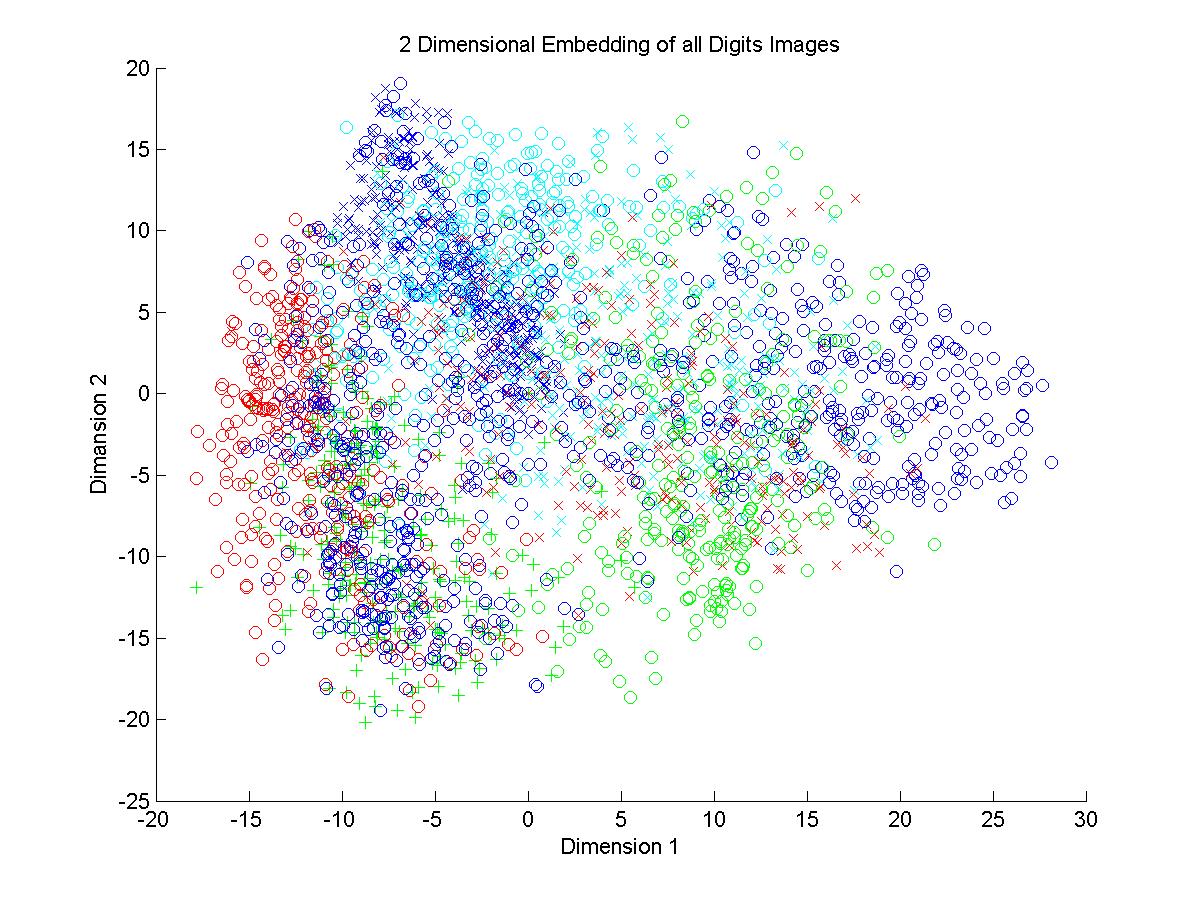
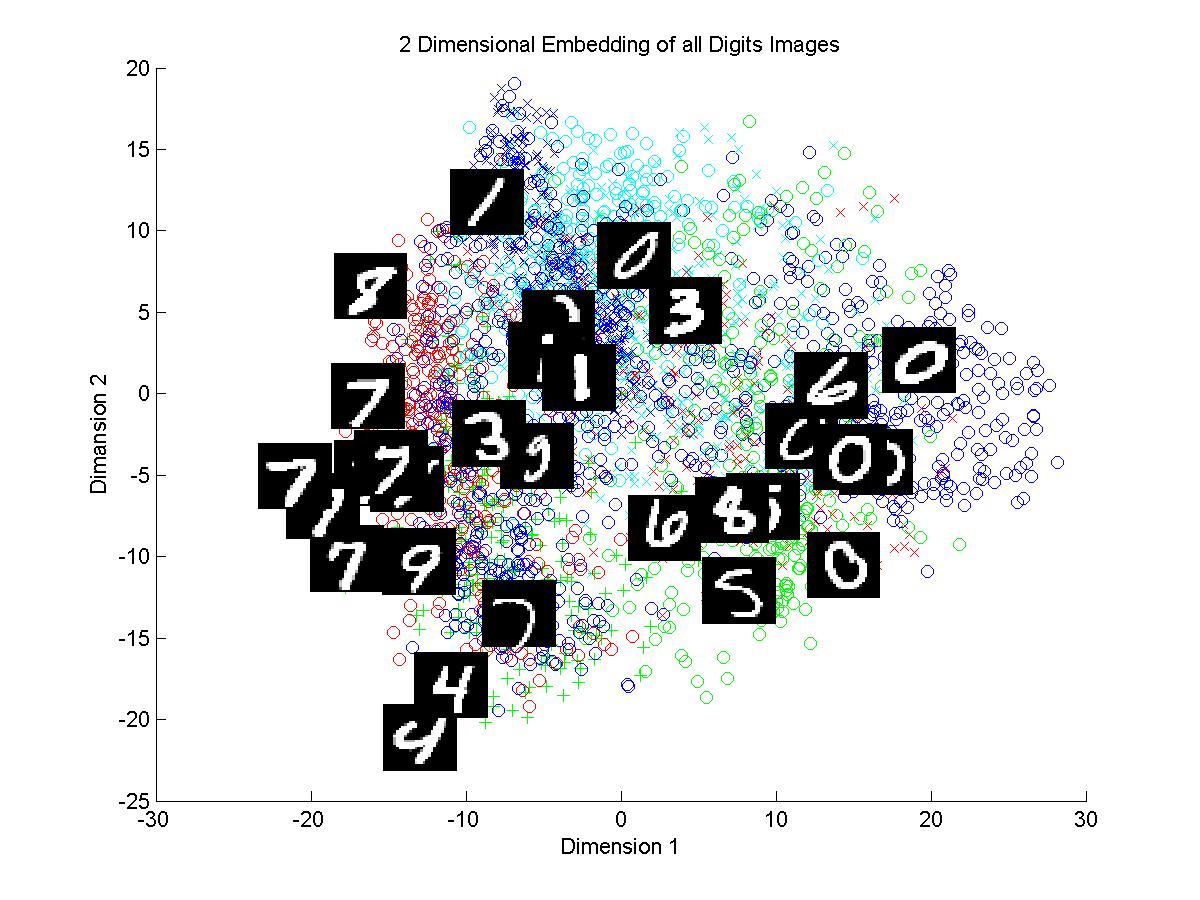
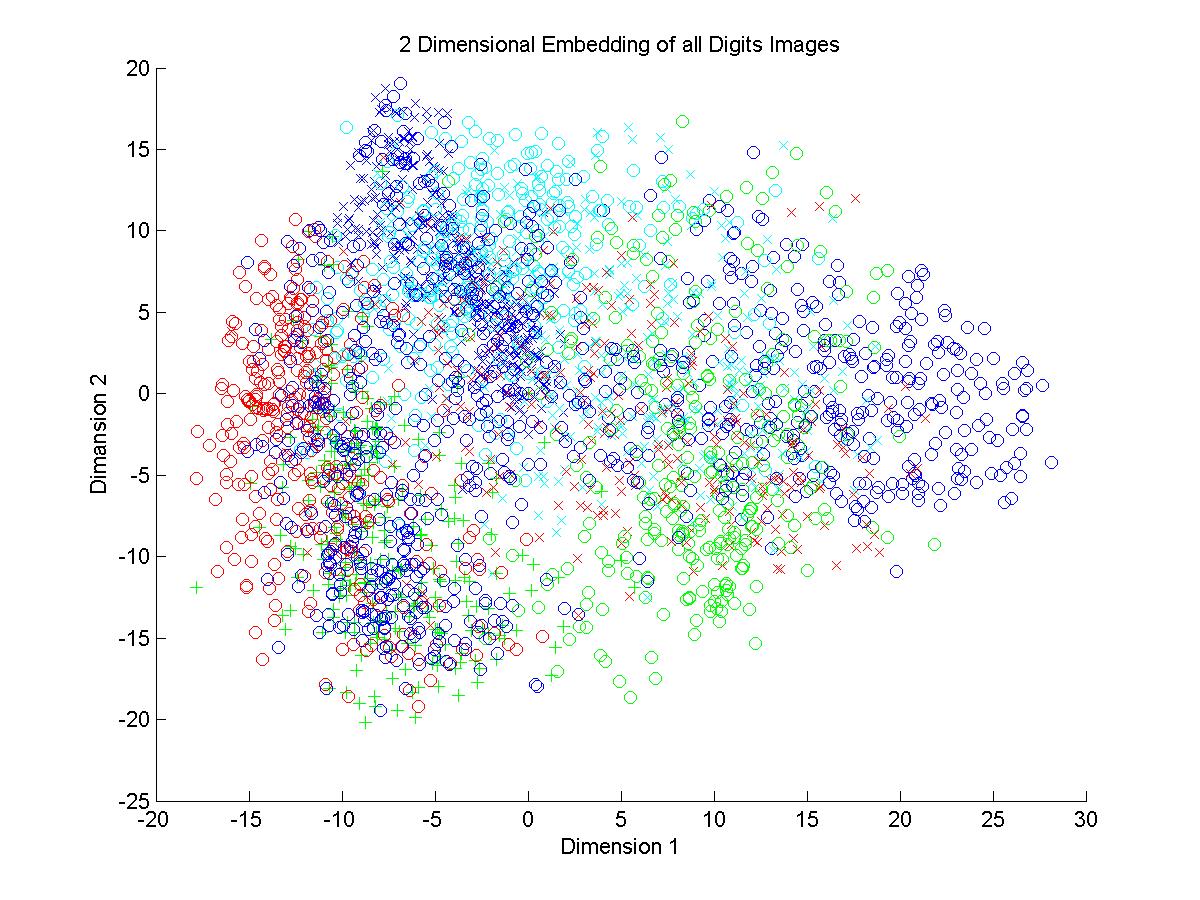
4.In the plots of all digits the clusters formed in both methods are highly intermingling. No boundaries are clearly visible. There is density of some of the digits but the digits like 0 is dispersed all
over the plot.
Overall we can see that the tangent distance method is giving high performance but the time taken for calculating tangent distance is way more than time taken by euclidean distance.
Deep Architecture: In deep level architectures there is an heiarchy of various levels of representations. Each layer represents some features. The higher level features are derived from the previous lower layer or level. The inspiration of this idea has come from human brain where the information is stored in a heiarchial manner. Here this method of DFN tries to learn the deep heiarchy inherent in data. Each unit of previous layer is connected to next layer by a set of weights. In each iteration of learning this weights are updated so that the learning model of data goes nearer to the actual data and able to predict the behavior of the data.
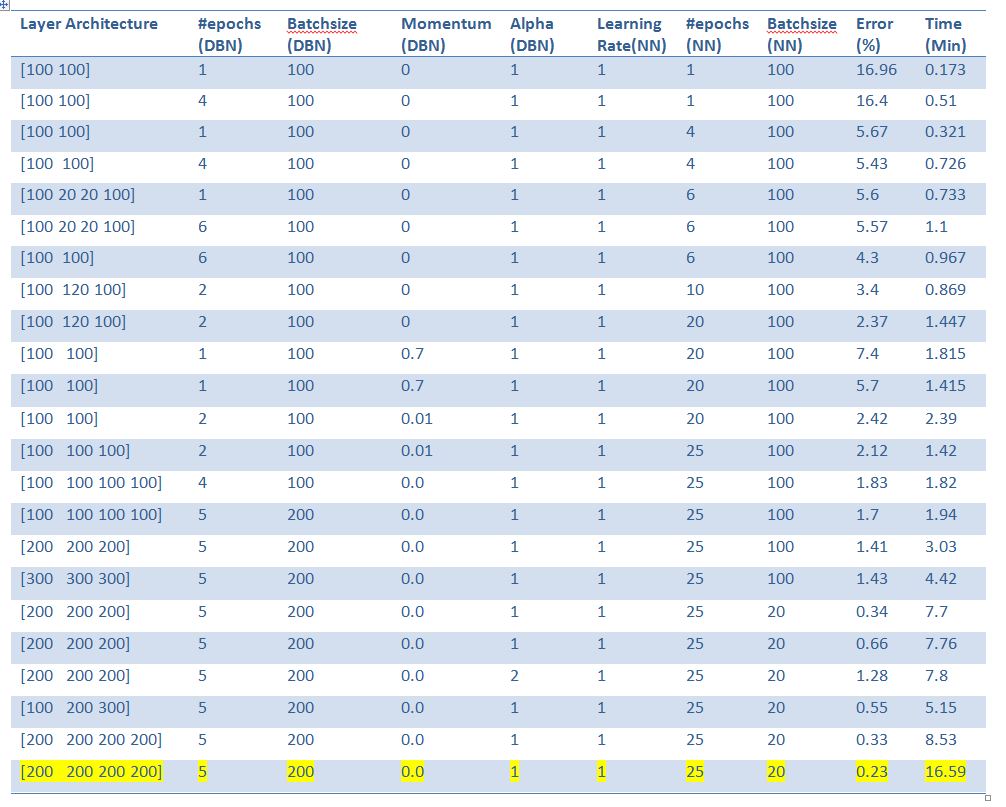
1.The minimum error% achieved is less than 1% and is 0.23 (achieved in the last entry).
2.Increasing the number of units in a layer first decreases the error but this trend gets reverses when we go above 300.
3.Increasing the number of layers in the architecture significantly decreases the error but the time taken gets increases.
4.Increasing no. of epochs of NN causes regular profound decrease in error however the decrement in error by increasing number of epochs of DBN is less significant. The minimum error obtained is produced by
making number of epochs of NN to 50 which takes 16 minutes!
. Hence if there is no constraint on time very low error perfomance can be achieved.