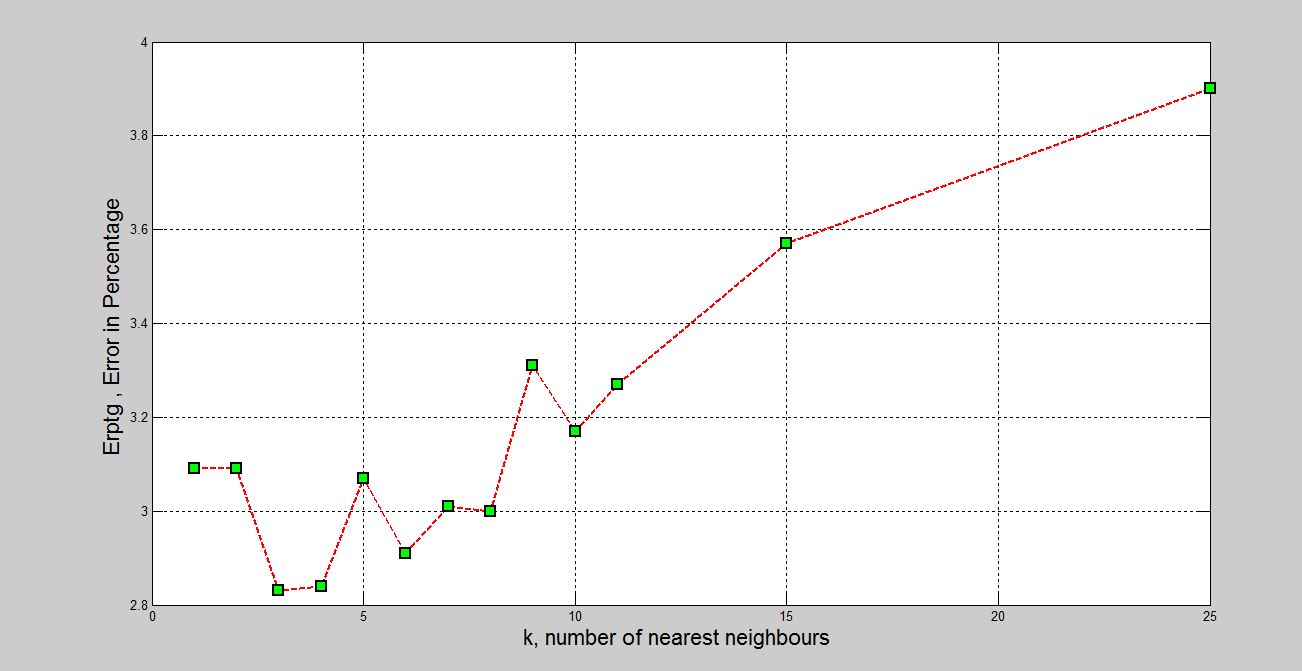
The least error for tht dataset occurs for nearest neighbours(K)=3 and as K increases the error percentage increases. Here Eucledian Distance is considered to calculate the nearest neighbours. for better results with Knn algorithm we can use bucketing or k-d trees approach.more details
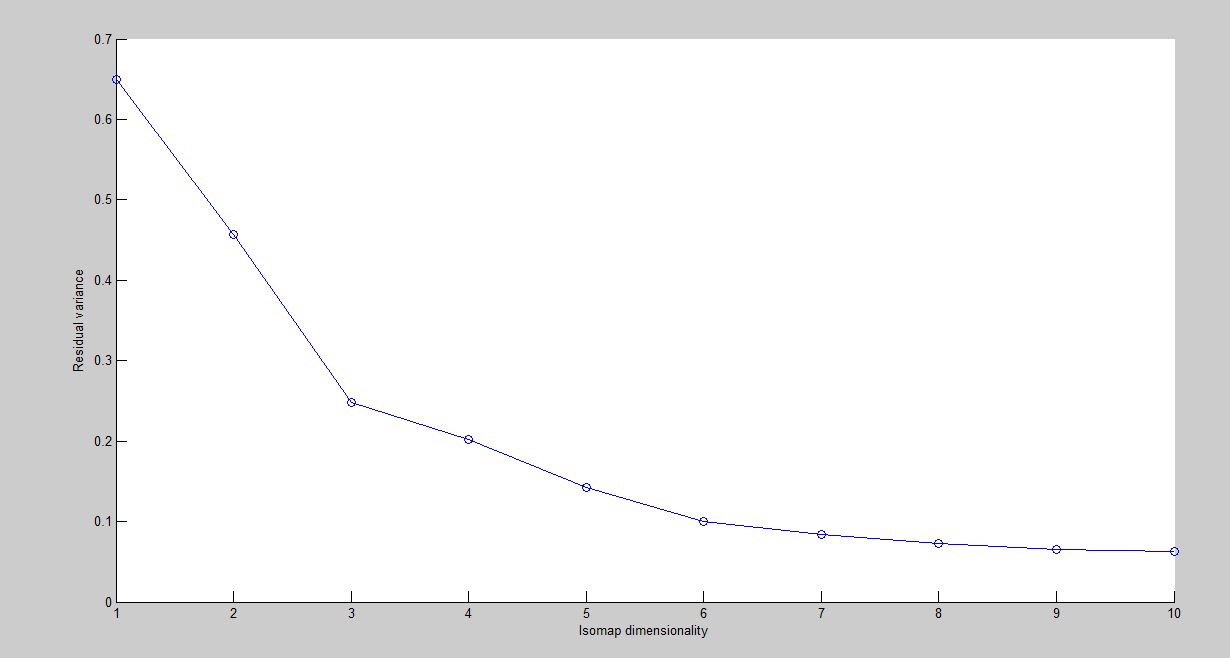
Isomap is one of several widely used low-dimensional embedding methods, where geodesic distances on a weighted graph are incorporated with the classical scaling (metric multidimensional scaling). Isomap,short for Isometric feature mapping, is an algorithm for manifold learning. Isomap is used for computing a quasi-isometric, low-dimensional embedding of a set of high-dimensional data points. The algorithm provides a simple method for estimating the intrinsic geometry of a data manifold based on a rough estimate of each data point’s neighbors on the manifold. Isomap is highly efficient and generally applicable to a broad range of data sources and dimensionalities. The isomap plotted for Euclidean distance for different dimensions against its respective variances is shown in th plot.
Ad the valeu of K increases the plot gets steeper!

Isomap is calculated by -Connecting each node with its K-NN neighbours.The connections are given using a weightedgraph with euclidean/tangent distances.-All the Geodesic distances are calculated based on the shortest path algorithm -The Multi Dimensional spacing is used to enbed in a lower dimensional space with same point to point distances as in orginal space
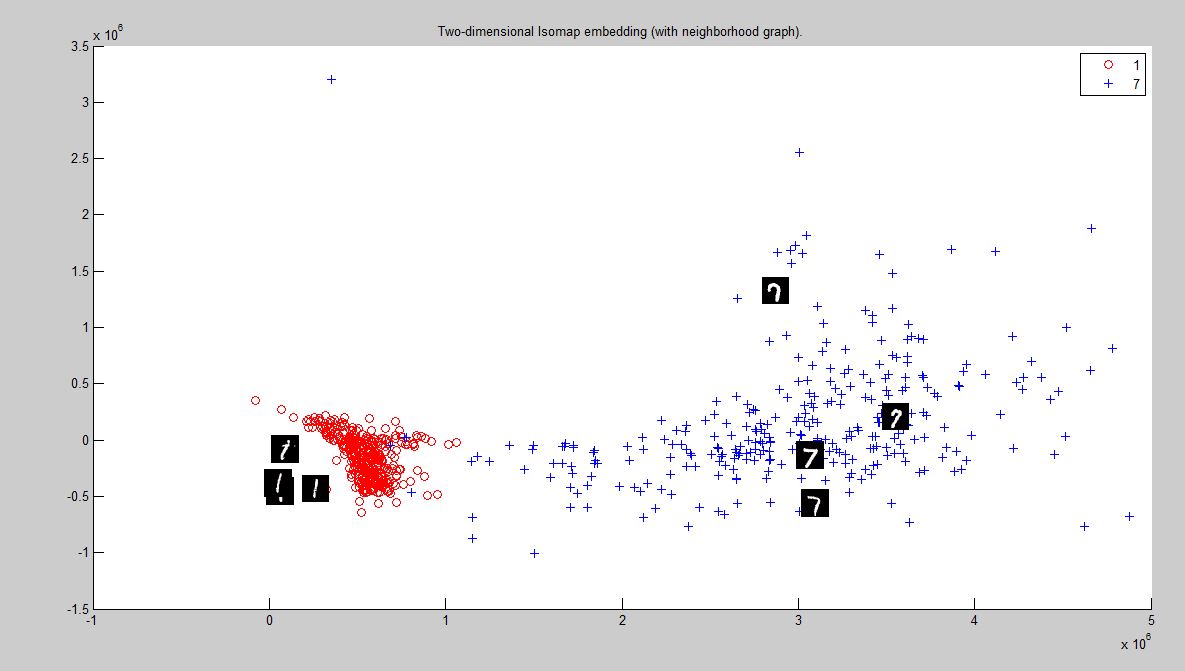
for 1 and 7 graph, as the image 7 gets slopier the cluster tends to get mixed up with that of 1 .And the reason for this seems to be the usage od euclidean distance to seperate the hand written numericals.
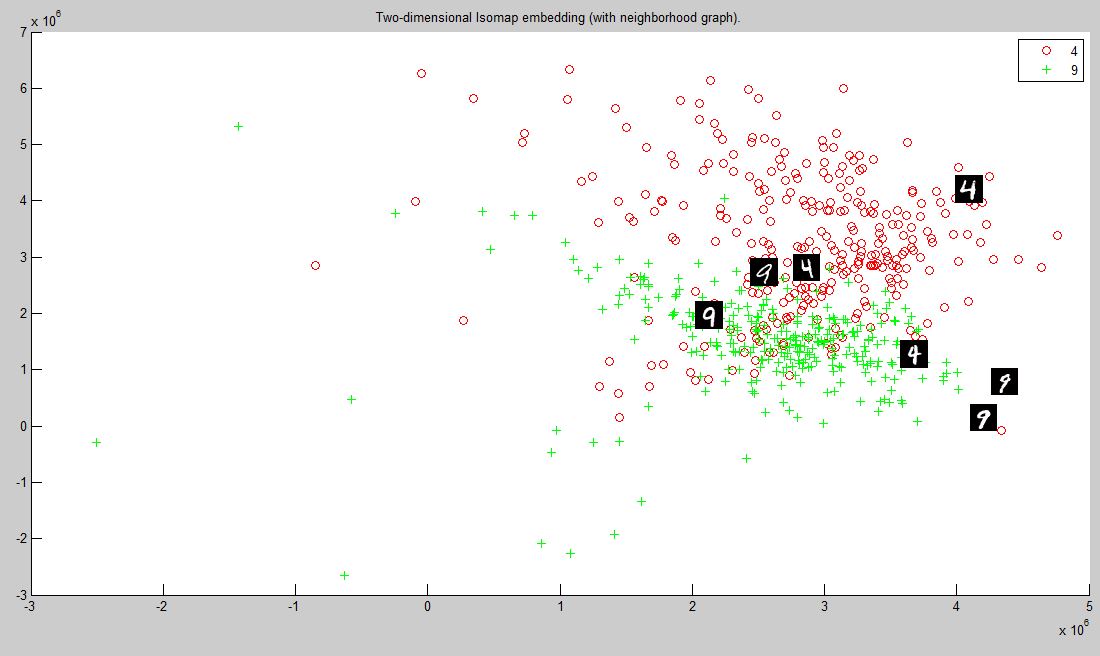
for 4 and 9 graph, this could seen even clearly , as the image 4 gets the cirlce part more round the cluster tends to get mixed up with that of 9 .The main reason seems to be the similar shape of both the numbers and the inability of euclidean distance to classify based on fine differences.
The clusters merge in many place when the shape of the numbers are almost similar,depending on many times the intensity of a line or the way its written(like an extra loop in number 2).
Comapared to Eucledian diatance , Tangent distance is a better measure to calculate distance and this can be viewed in the way the clusters 1 and 7 seperate out with such ease.
 C
C
The effectiveness of tangent distance in classifying 4 and 9 is far better than that of euclidean distance
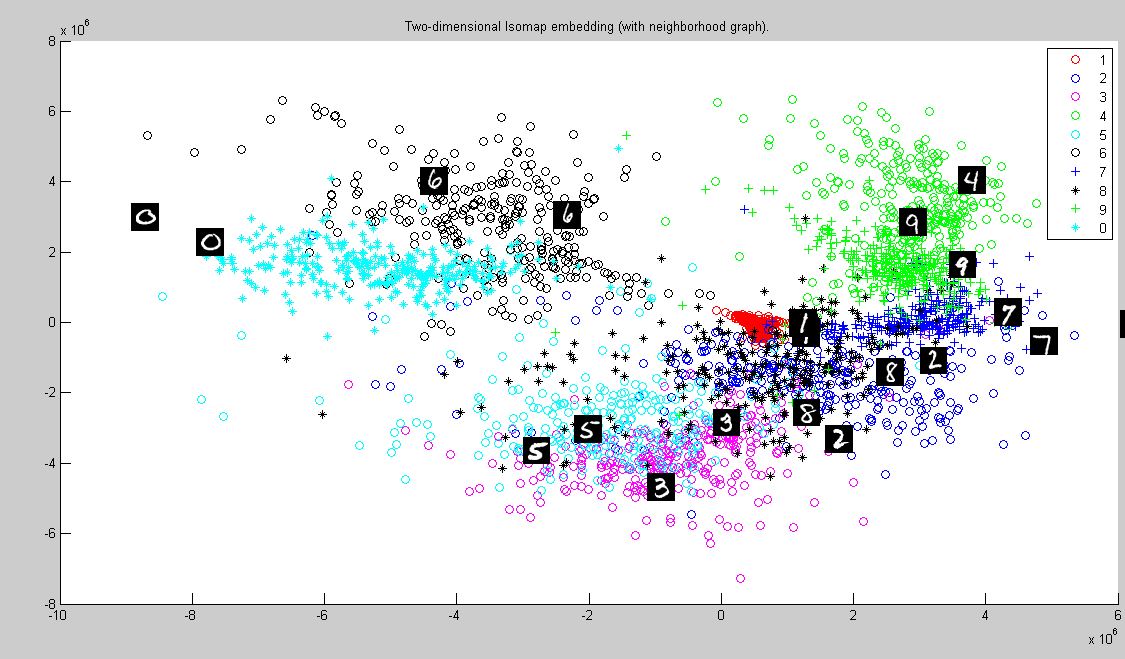
Different numbers form clusters depending on the similarity of their shape.But as a whole it can be said Tangent distance is a far better way for classifying the hand-written numericals compared to euclidean distance.
Deep learning refers to a sub-field of machine learning that is based on learning several levels of representations, corresponding to a hierarchy of features or factors or concepts, where higher-level concepts are defined from lower-level ones, and the same lower-level concepts can help to define many higher-level concepts.RBMs(Restricted Boltzmann machines) can be stacked and trained in a greedy manner to form so-called Deep Belief Networks(DBN).This methodlearns to extract a deep hierarchial representation of the training data.It implements a greedy unsupervised layerwise training method for updating the parameters. Each layer has certain number of hidden units(sigmoid functions).Each unit is connected to every unit of its adjacent hidden layer through wieghted edges. Training is done layerwise.Output of the first layer being the input for second and so on.Parameters are tuned based on the error in output w.r.t to desired results. This DBN is unfolded into a simple NN with output layer corresponding to the 10 digits. This NN is then trained using the gradient descent algorithm for updating weights. The final updated weights are then tested on the MNIST testdata set
 />
/>
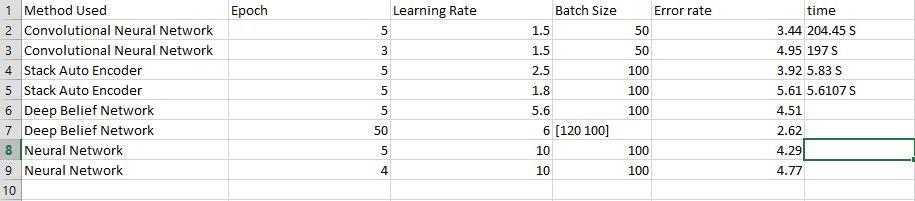
In most cases the Error rate decreases with Increase in number of epochs but after a certain value it ceases to have any effect on the error rate, Decrease in BatchSize improves the effeciency but at the same time the runtime of the program increaes significantly too,Increase in learning rate also decreases error rate for a certain range . Performance order is CNN > SAE > DBN > NN .More data about these reults are included in the source codes.