Vishal Kumar Gupta 10817
Matlab Code KNN_classifier.m for plotting error rate vs "k".
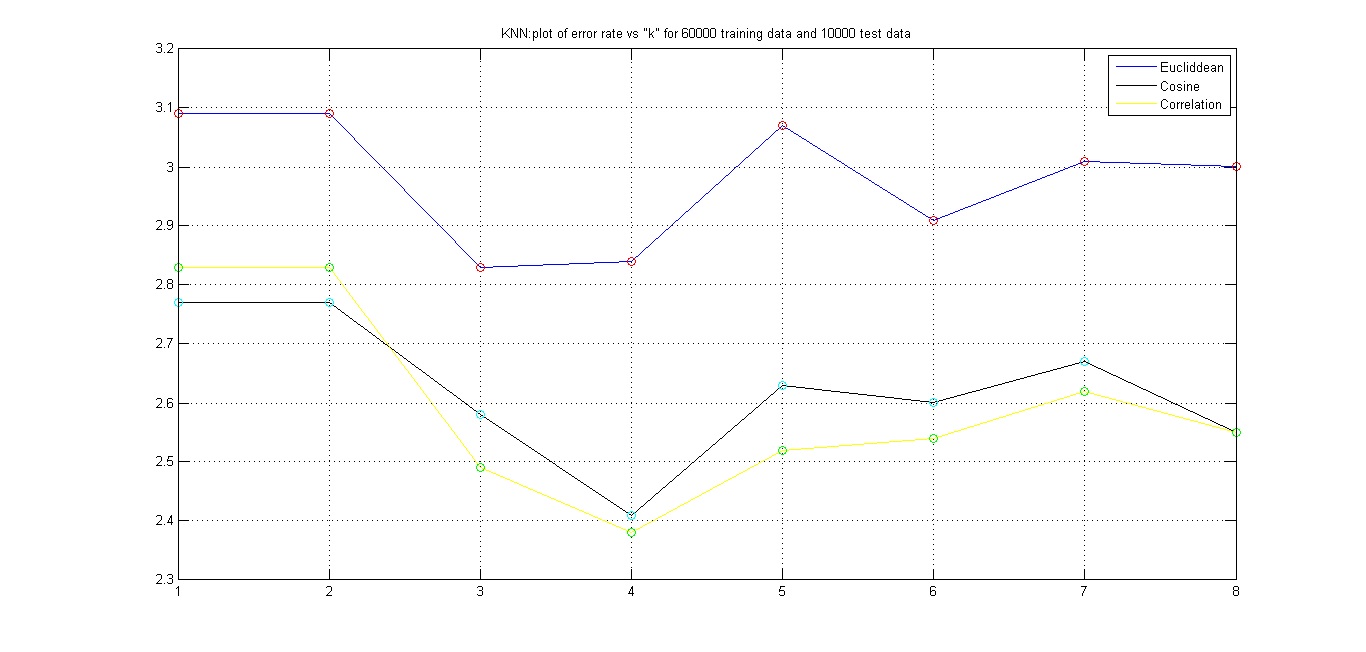
As shown in the above plot, we conclude that "Euclidean" distance measure is not an efficient way of measuring distances in higher dimension. The reason being Euclidean distance measure doesnot takes into account the coorelation among the various dimension of feature space.However, the results so obtained by using "Coorelation" distance measure and "Cosine" distance measure. For k = 4, we get the minimum error rate.
Isomap is used for computing a quasi-isometric, low-dimensional embedding of a set of high-dimensional data points. The algorithm provides a simple method for estimating the intrinsic geometry of a data manifold based on a rough estimate of each data point's neighbors on the manifold. Isomap is highly efficient and generally applicable to a broad range of data sources and dimensionalities.It is a non linear technique of dimensionality reduction unlike PCA which is inherently linear.
(i) Cluster plot for Digits '1' and '7' -(Matlab Code)
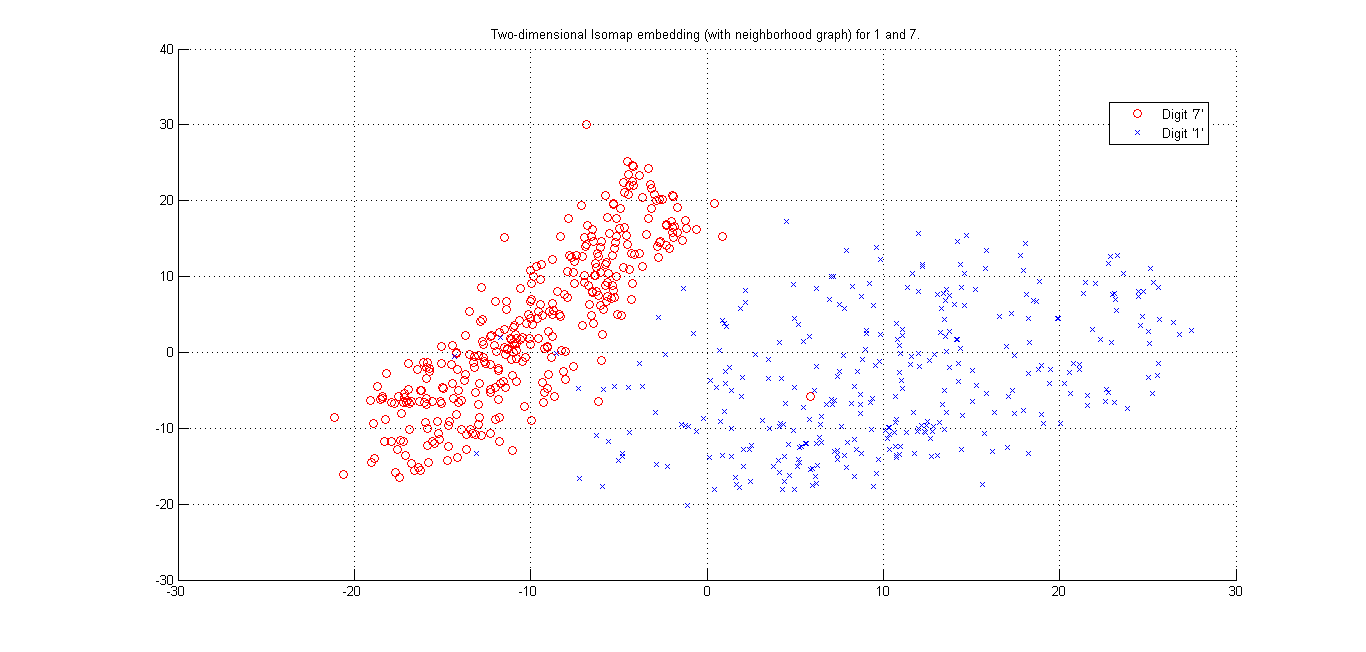
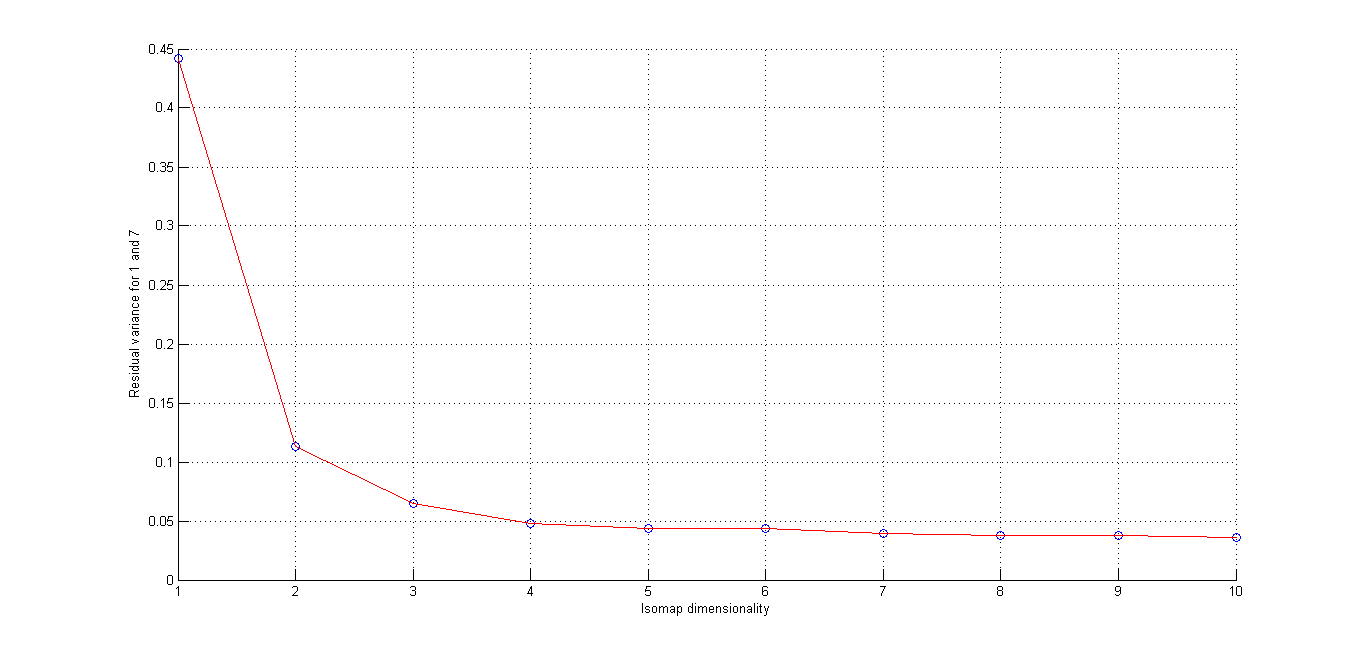
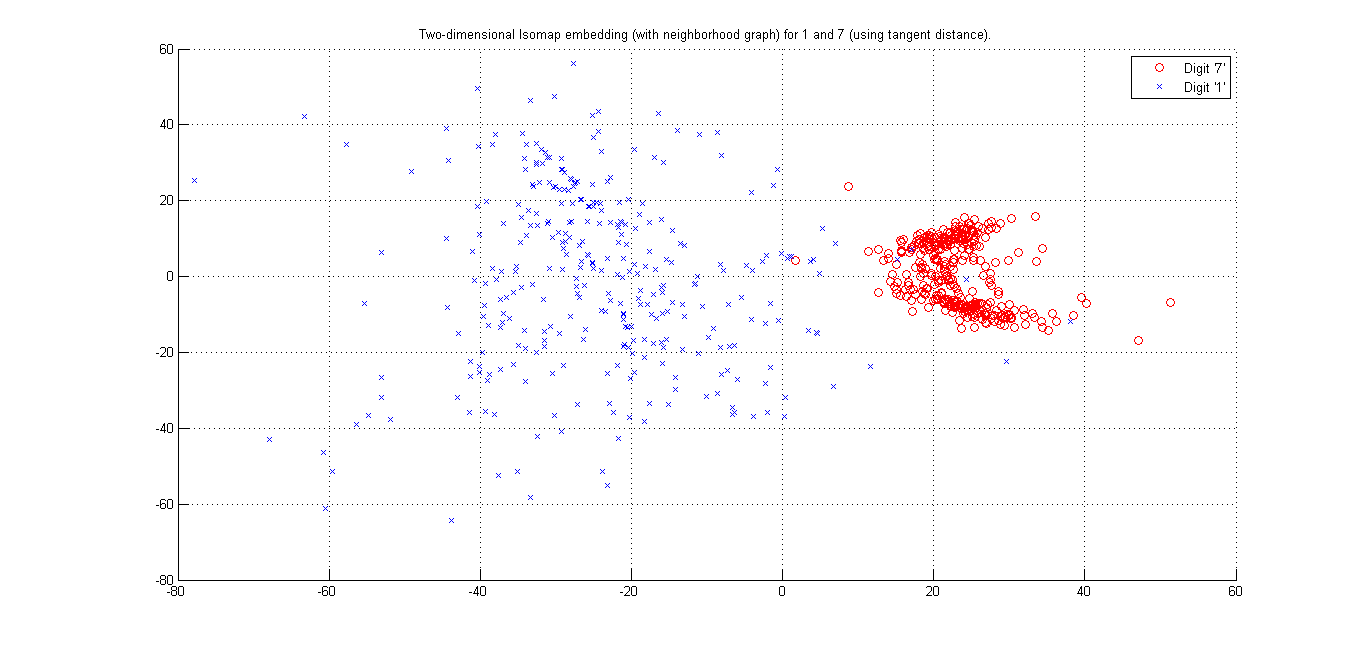
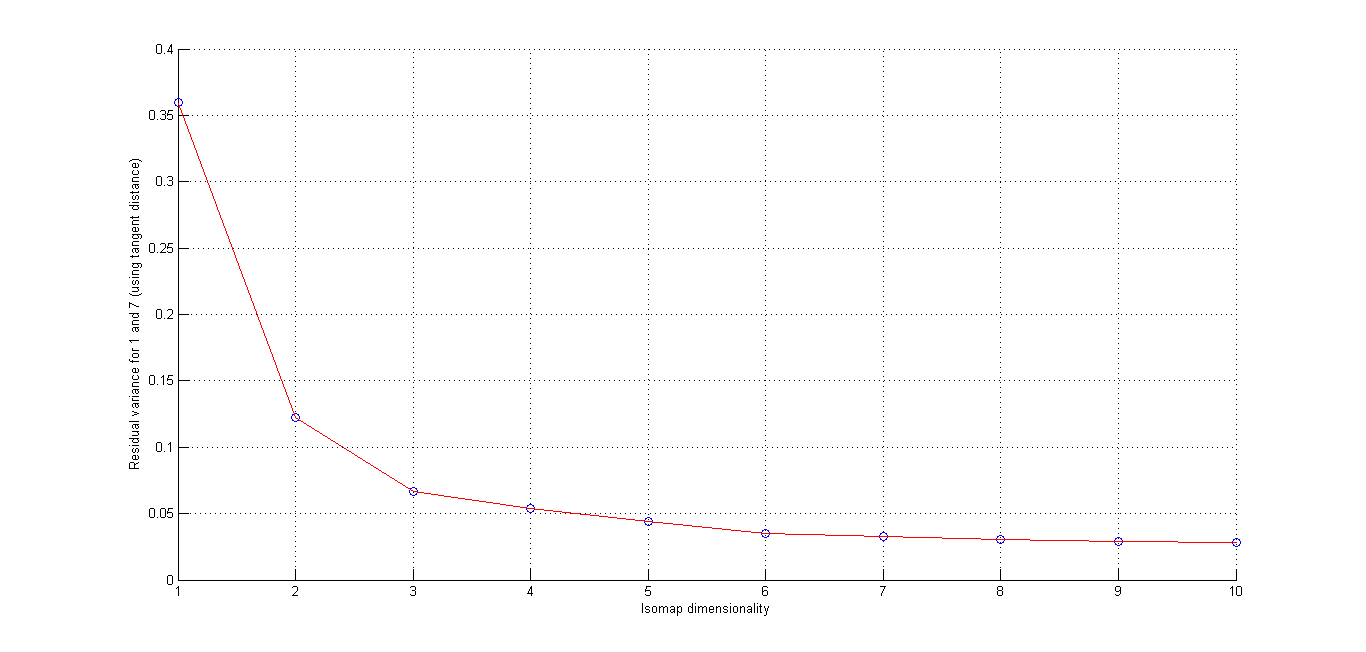
Here we seee that using L2 distance and Using Tangent Distance, we get best cluster by using tangent Distance. Resudal plot also shows Tangent Distance gives best clustering results.
(ii) Cluster plot for Digits '4' and '9' -(Matlab Code)
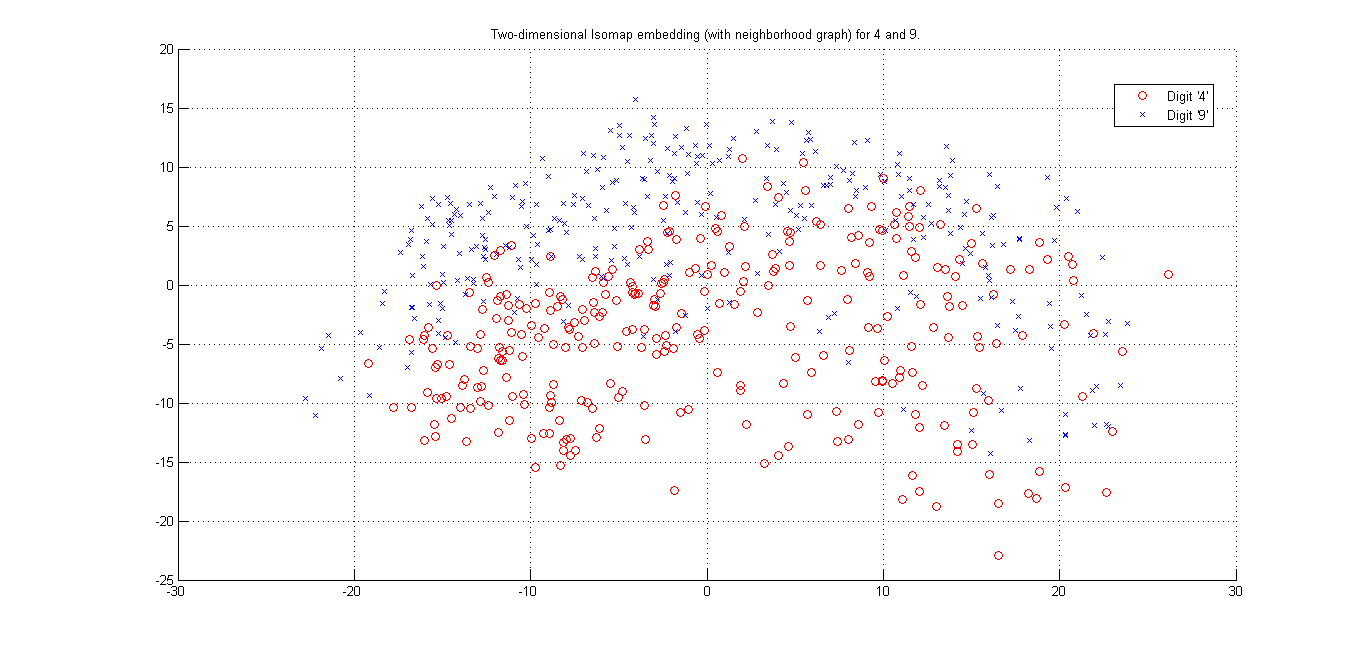

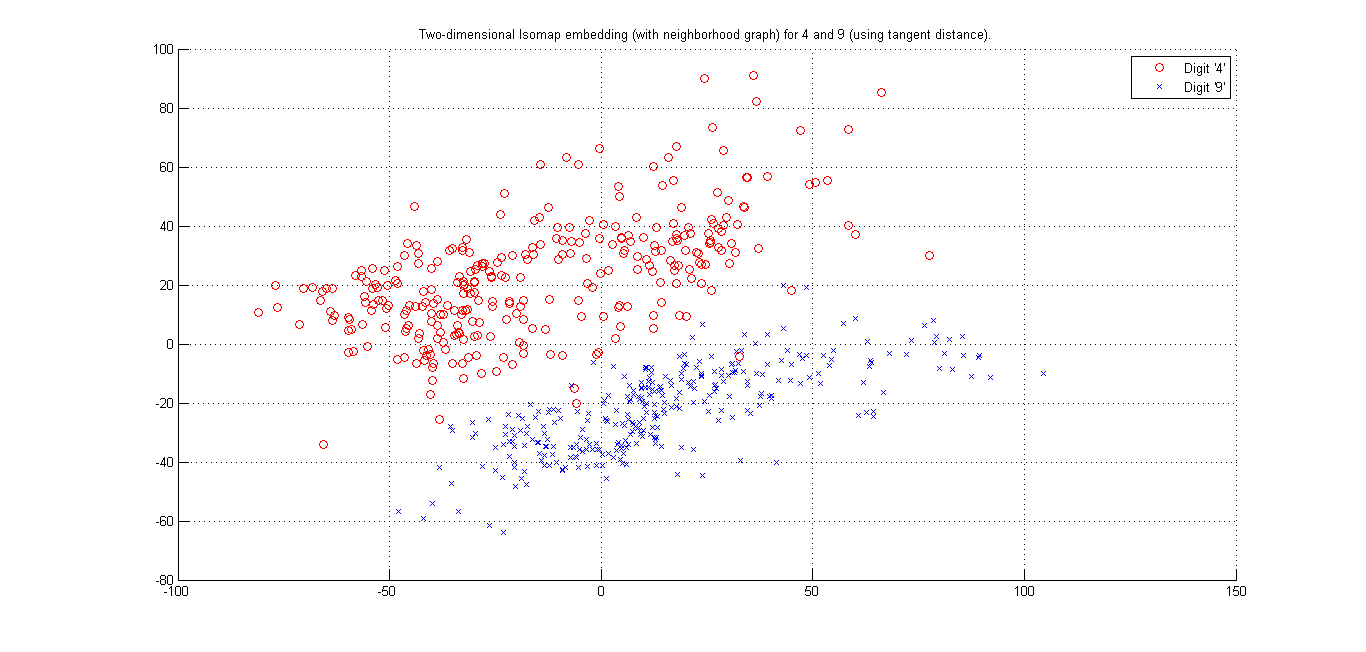
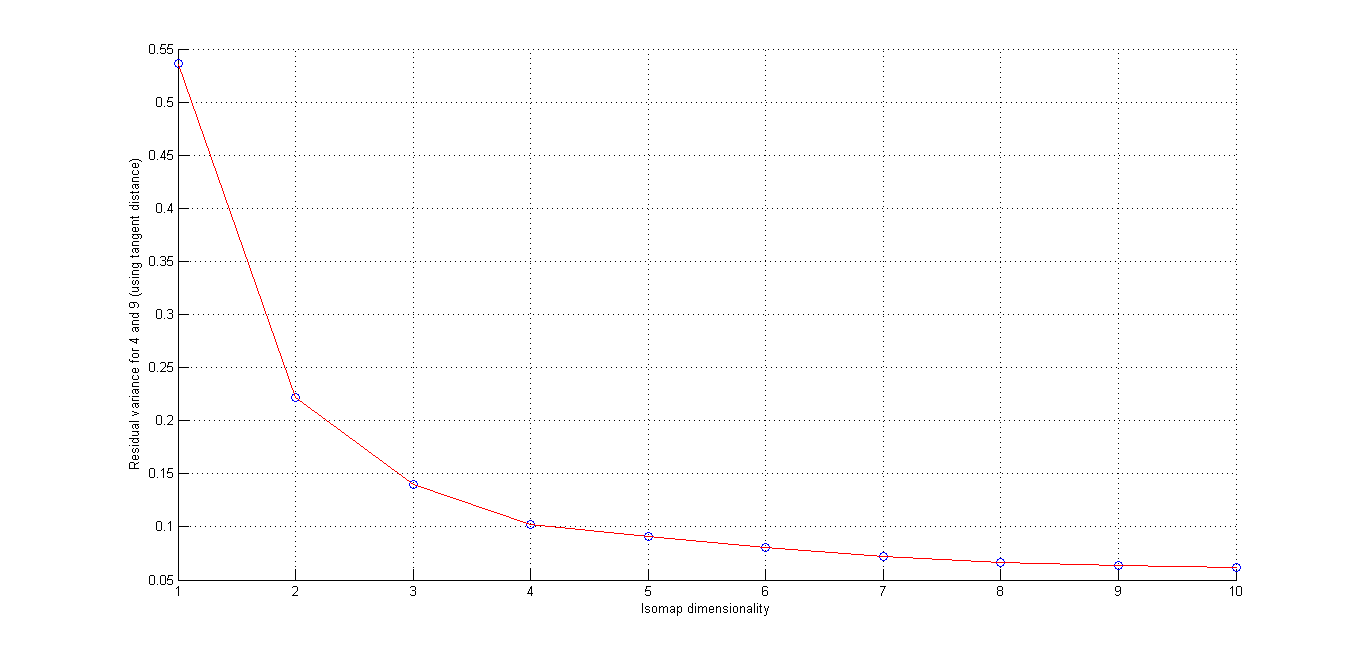
Here we seee that using L2 distance and Using Tangent Distance, we get best cluster by using tangent Distance. Resudal plot also shows Tangent Distance gives best clustering results.
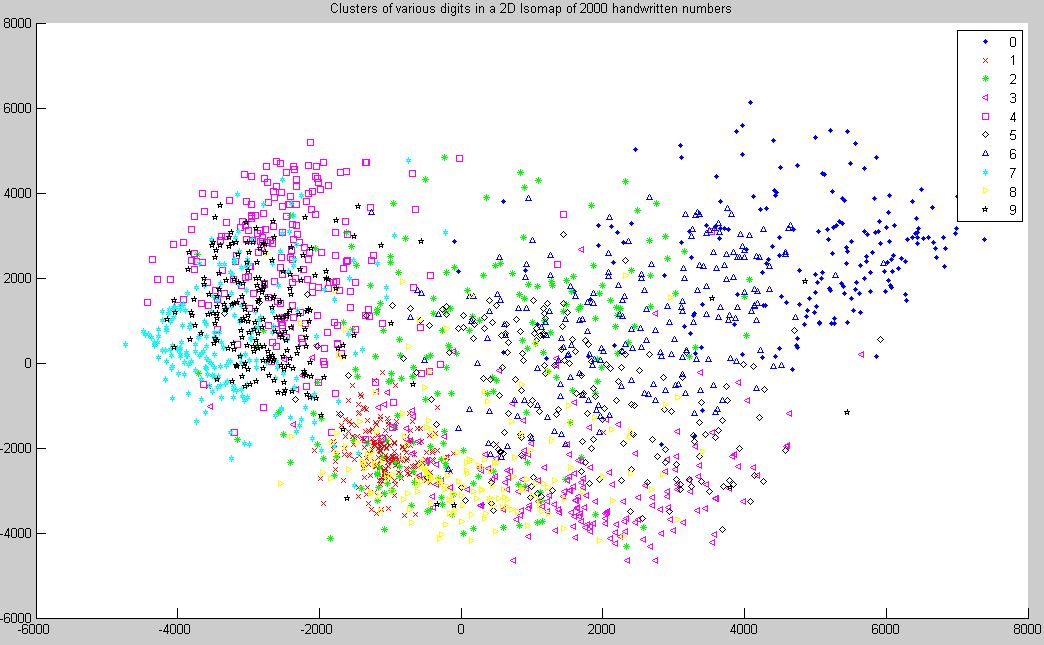
(iii) Cluster plot for all Digits -
(iv) Cluster plot for Digit "2" -
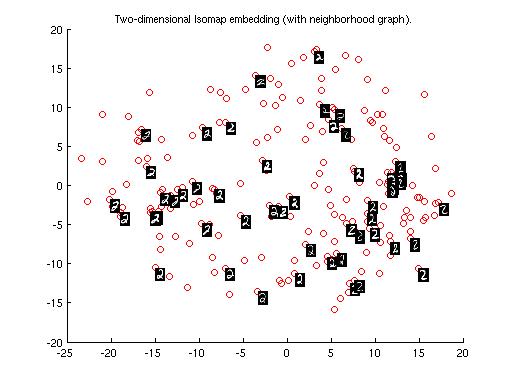
This plot shows the variation of different forms of Digit "2". Bascically it shows the curves in the digit "2".Curve in the lower part of Digit "2" lies in the left part of plot which gradually varies to as we move to the right part of plot.
Deep Architectures are advanced form of neural network which uses greedy layerwise procedure for training using gibbs theory of sampling. It is a form of unsupervised learning in which higher order features are learned and represented in a much better fashion. The procedure of training is explained as follow: Initially the input layer is reproduced with the help of one hidden layer.Then this hidden layer is used as input for the next hidden layer i.e to say the network is trained in a greedy manner. Since layerwise trainng is adopted, training is actually fast as compared to conventional neural networks. After Desired number of hiden layers were trained those features were then used for classifiction.Each hidden unit in the network is representative of some unique features.Since the learning process is unsupervised the network itself recognizes patterns and the features that are learnt are very good.
These are the test cases that were taken into account.
(i)(Best Case)
Architecture structure: [200 100 200]
No. of Epochs = 20
Learning Rate = 1.5
Error Rate = 2.7
Time of Running Code = 5.65 minutes