Multimodal Neural Language Models
Kiros, Salakhutdinov and Zemel,
Department of Computer Science,
University of Toronto
Paper review for CS671A
Amlan Kar
Neural Language Models
- Aim to create distributed representations of tokens using neural networks
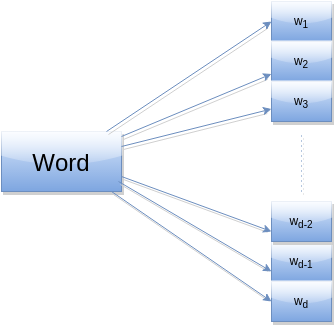
Distributed representation
Why ?
- No fabricated features
- Reduces the curse of dimensionality
- Possibility of distance metrics that entail semantic similarity
- Recent advances outperform n-gram models
Log-Bilinear models (Mnih & Hinton, 2007)
Log Bi-linear Model
- Feed-forward neural network with 1 hidden layer.
- Works on distributed word models (word vectors)
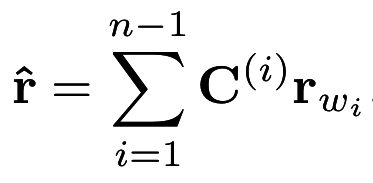
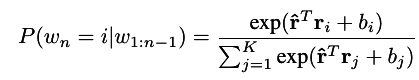
Bias Vector
Modality Based Log Bi-linear Model (MLBL-B)
- For each training tuple of words, there is an associated vector X (of the desired added modality)
- Treated as a simple additive bias
Bias Vector
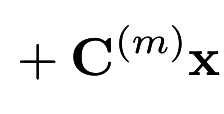
Factored 3-way Log Bi-linear Model (MLBL-B)
- Uses a word representation matrix for each component of the added modality
- But this is in 3D (a tensor) ! How do we get the final to output layer weights ?
Weights determined by modality vector x
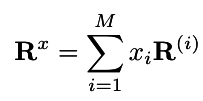
Intuition ?
- Think of it as a weight matrix conditioned to the image input it is getting
- Effectively biases context words dynamically based on added modality input
Problems ?
- Using a 3-way tensors entails requirement of weights of a cubic order ( K x D x M )
- M and D are generally high dimensional !
- Puts constraints on vocabulary size K !
Solution ?
- Factor R into three lower-rank matrices

where,
Paper review for CS671A
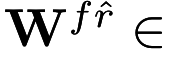
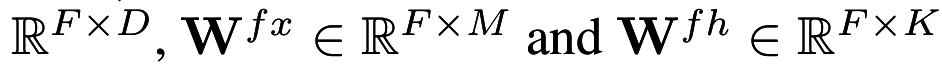
Tensor Factorization ? What is F ?
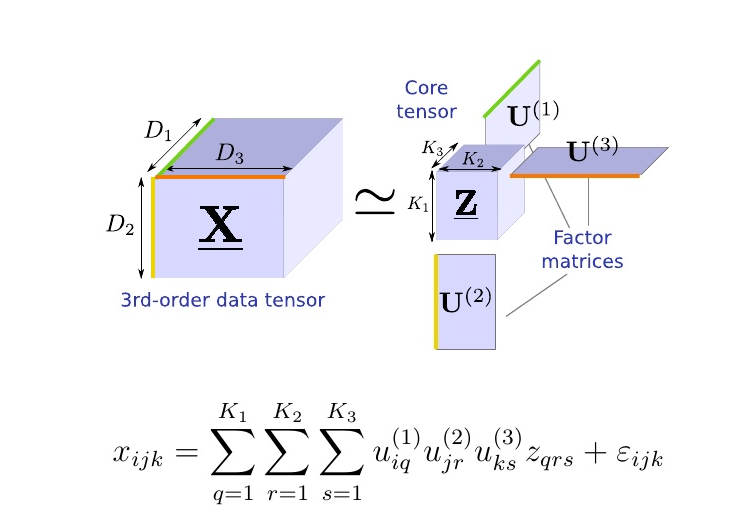
Image from Kohei Hayashi's talk on Generalization of Tensor Factorization and Applications
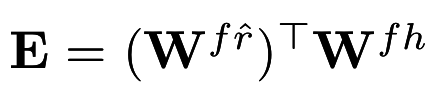
This E can now be treated as our word embedding space !
This is different as it now incorporates multimodal information !
Factor Outputs - Putting in the multimodality
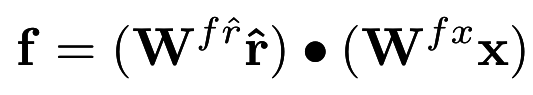
This is basically the dot product of the word representation vector with the image representation vector after projecting them to a Fx1 vector using the tensor factorization matrices.
We shall finally use f to generate the next word just like in the Log-Bilinear model
How ?
Use each column of
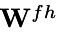
Joint Image-Text Feature Learning
- Very difficult to train on each image-word pair
- Given training images, learn a dictionary of features using spherical k-means on random rxr patches of the images
- Convolve the images with kf features to obtain a 3-D matrix
- On each slice of the matrix, perform max-pooling to obtain a GxG grid of most relevant features
- This leaves us with a GxGxkf input matrix for the CNN
- The final output of the CNN is used as the bias vector in the computation shown before.
